Introduction
Every year, we can get significant data from traffic. Traffic flow, average speed, average delay and all information are important for traffic forecast and management. In the past, it’s almost impossible to analysis data on this scale. Fortunately, the development of cloud computing technique saves us from the heavy computational works. In this post, I will introduce the traffic big data works conducted by our team.

Objectives
With the traffic data, we can do many things to make the traffic a better place. In our team, the main objective of data analysis is making a prediction, which is helpful for all traffic participants. The main concerns are listed as below:
- Demanding forecast of taxi
- Forecast of bus passenger volume
- Forecast of traffic volume on highways
- Forecast of travel time on highways
- Commuters’ travel characteristics
- Forecast of selecting bus lines
- Analysis of Cause of traffic accident
- Forecast of urban road travel time
Technological supports
There are many ways to handle magnanimous data. The related techniques and software are listed as follows:
- Machine learning
- Hadoop/Spark
- New technology exploring and pre-researching
- Abundant knowledge of traffic
Predict traffic volume on highways
Data
Average travel time, speed and traffic volume from 15000 detectors placed on California highway in 2013.
Method
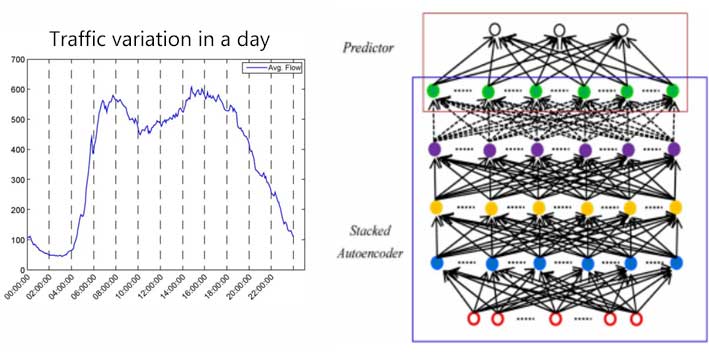
Results
Comparison between different prediction model:
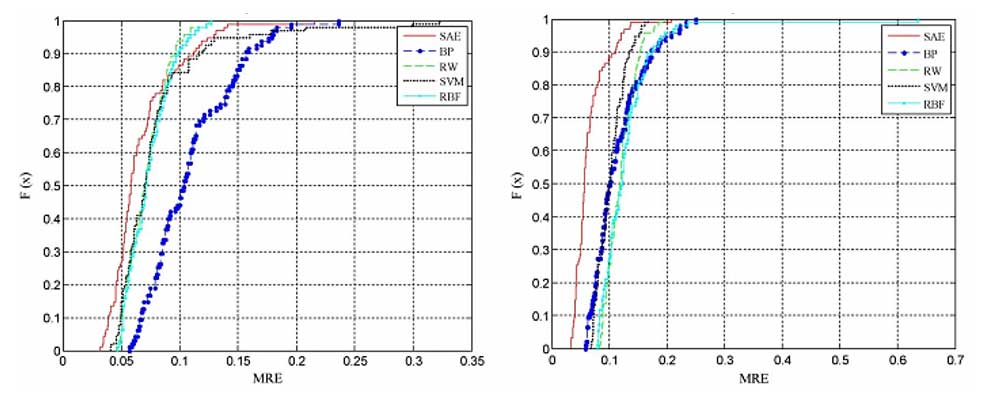 When the traffic volume on the highway is more than 450veh/15min:
When the traffic volume on the highway is more than 450veh/15min:
- The accuracy of 15-minute prediction is over 90% for 86% of the roads.
- The accuracy of 30-minute prediction is over 90% for 88% of the roads.
- The accuracy of 45-minute and 60-minute prediction show is over 90% for 90% of the roads.
Multivariate data fusion analysis
Data Source
Modules
- traffic volume analysis
- an operational state analysis of road segment
- an operational state analysis of the intersection
- trip distribution character analysis
Technologies
- Track recognition
- Data mining
- Multivariate big data fusion
Procedures
- Road traffic volume analysis
- Operational state analysis of road segment
- Operational state analysis of intersection
- Trip distribution character analysis
Result
5 kilometers around Nanjing South Railway Station—road speed:
Public transport demand prediction
Data
Bus card data of Guangzhou Bus and Guangfo Bus from August 1 to December 31 in 2014. From the behavior model of fixed crowd in public transport, we can build a Passenger Flow Forecast Model for Bus Lines and predict the number of trips hourly for each line in the coming week.
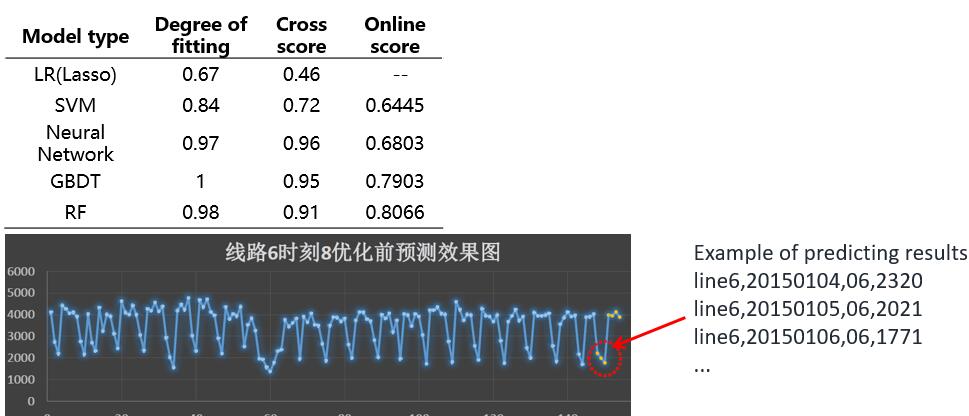
Result
- The Neural network is good in this case, but it’s not unstable. The main reason about that is over-fitting.
- GBDT and RF both got a high performance on final online evaluation.
The vehicle routing problem of public transport
Data
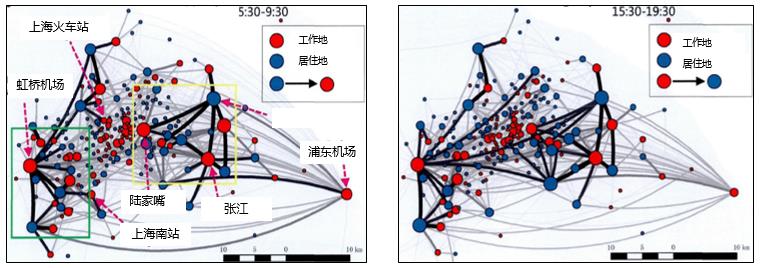
The data comes from taxi, social media and mobile in Shanghai. We build a model to reveal the relation among residents commuting behavior and identifying urban residence and employment spaces.
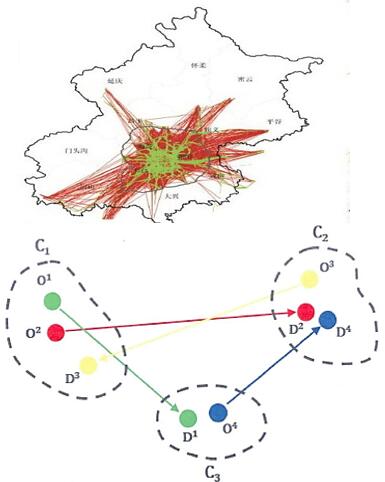
Method
- Traffic grid OD clustering
Result
We can find the hot areas of origins and destinations from the result. As a result, the travel time and the law of commuting can be judged approximately.