关于使用RNN进行时间预测的问题,中文相关教程还很少。所以本文结合国外几篇教程与自己的使用经验,详细描述如何使用Keras中的RNN模型进行对时间序列预测。
开发环境
文本所使用的开发环境如下:
Windows 10
Python 3.5
Keras 2.0.6 (backend: tensorflow-gpu)
如果使用 Keras 的话,选择 Tensorflow 或者 Theano 理论上均可以正确运行。
对于 Windows10 而言,Tensorflow现在应该并不支持 Python2 的环境,官方的指定环境为 3.5。
如果你用 Anaconda 的话,默认下载下载的是3.6的环境,安装 Tensorflow 需要再折腾一番。所以我个人的建议是先安装最新的 Anacoda, 然后把默认的环境改为 3.5 。具体命令如下:
conda install python=3.5.0
现已支持 Python 3.6,直接安装即可。
任务描述
本文的主要任务就是进行时间序列预测,主要模型为 Recurrent Neural Networks (RNNs)。数据为苏州市公共自行车某个站点可借车辆数量的数据,一分钟一次。这样的自行车都是有桩的,一个站点有40个桩,过满或者过空都不太好。我们这些历史数据去预测将来的可借车辆数。

数据下载:bike.csv
num表示自行车数量,weekday表示星期几,hour表示小时。一共45949条数据,这些数据是按一分钟一次的顺序排列的。用RNN进行预测的话,实际上用num字段就够了,其他两个字段作为额外的参考信息,读者不妨利用这两条信息构建更复杂的模型,提高预测精度。
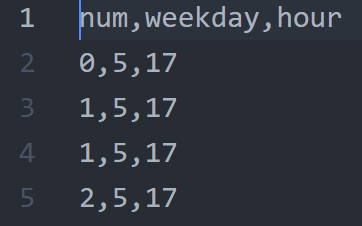
接下来我们将用多层LSTM 的RNN神经网络去预测这些序列的值,简单来说,我们有9个连续的num,那么如何预测第10个num是多少?(知道前九分钟的num,预测下一分钟的num)
我们首先import 各种需要的依赖,然后定义模型进行训练,最后预测数据,利用 matplotlib 画出最终预测的结果。
加载依赖库
import matplotlib.pyplot as plt
import numpy as np
import time
import csv
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Dropout
from keras.layers.recurrent import LSTM
np.random.seed(2017)matplotlib,numpy,time分别用于画图、python数组、系统时间。csv模块可以直接从文本里面读取数据,也可以使用pandas或者numpy。models是 Keras 神经网络的核心。这个对象代表这个我们所定义的神经网络:它有层、激活函数等等属性和功能。我们进行训练和测试也是基于这个models。Sequetial表示我们将使用层堆叠起来的网络,这是Keras中的基本网络结构。Dense, Activation, Dropout这些是神经网络里面的核心层,用于构建整个神经网络。Dense 实际上就是 Fully-connected 层;Activation是激活函数,它会通过Relu, Softmax 等函数对上一层产生的结果进行修改;当神经元过多的时候,可能效果并不好,因为容易导致过拟合的现象,Dropout是将上一层神经元进行随机丢弃,有助于解决过拟合的问题。LSTM是经典的RNN神经网络层。LSTM 的内部结构非常复杂,如果想要深入了解的话可以看以下材料: (Chris Olah’s Understanding LSTM Networks )np.random.seed是随机种子,我们在下面的会进行随机数的操作,为了这一过程的可重复性,我们设置一个随机种子,让每次随机结果相同。
准备数据
def get_data(path_to_dataset='bike_rnn.csv', sequence_length=20):
# 数据的最大行行数
max_values = 45949
with open(path_to_dataset) as f:
data = csv.reader(f, delimiter=";")
bike = []
nb_of_values = 0
for line in data:
try:
bike.append(float(line[0]))
nb_of_values += 1
except ValueError:
pass
# 如果大于等于最大行数就退出
if nb_of_values >= max_values:
break原始数据有三个字段,我们只关注第一个num字段。原始数据文件有45949行,一行代表一分钟,也就是说大约一个月的数据。
result = []
for index in range(len(bike) - sequence_length):
result.append(bike[index: index + sequence_length])
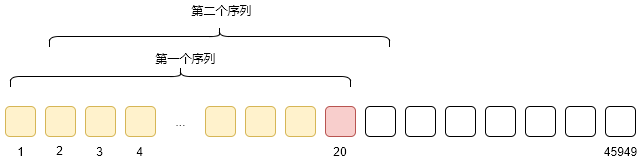
result = np.array(result)我们的bike实际上按照顺序加载了所有的num数据,我们需要把这个一长串的数据,按照我们的方式进行分割。本文以20个的长度为例,来创造这样一个个20个长度的序列。也就是说,我们用前19个值,去预测第20个值,然后对比预测至与第20个的真实值。通过这样的误差不断的优化我们模型。以上的循环取序列的方法如下图,取完20个然后向后退一格,直到不能再取。
result_mean = result.mean()
result -= result_mean
print("Shift : ", result_mean)
print("Data : ", result.shape)如果数据预处理过的话,训练效果往往更好 (cf Y. Lecun’s 1995 paper, section 4.3)。而且就时间序列的数据类型而言,我们并不希望处理后的数据和真实数据偏差非常大,所以本文用了一直非常简单的方法进行数据的预处理工作。首先计算整个数据的平均值,然后把每个原始数据都减去这个均指,这样数据整体的变化就在0上下波动。
row = int(round(0.9 * result.shape[0]))
train = result[:row, :]
np.random.shuffle(train)
X_train = train[:, :-1]
y_train = train[:, -1]
X_test = result[row:, :-1]
y_test = result[row:, -1]下一步操作是把数据分为训练集和测试集,输入和输出。我们选了10%的数据作为测试,90%的数据进行训练。每个20长度的序列的最后一个值作为目标值,其余前面的部分作为输入值。输入值输入到模型,目标值是真实值,也就是模型想要达到的目标。
np.random.shuffle(train)的含义就是将所有训练数据随机打乱,这样在训练的时候每次喂给模型的数据的概率分布是均匀的。简单来说,如果不打乱的数据的话,在连续的训练过程中,很容易让模型的weights空间陷入局部最优,打乱这些数据能够更好的让模型的参数优化过程更好、更稳(更多解释见:https://datascience.stackexchange.com/questions/24511/why-should-the-data-be-shuffled-for-machine-learning)。而为了方便可视化我们预测结果,对测试数据并没有进行打乱的操作(常规操作)。
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
return [X_train, y_train, X_test, y_test]最后一件事就是根据Keras模型的要求调整输入数据格式。我们利用numpy对数组进行reshape操作,这里输入的每一个最终数据都是一维的,他们只有一个特征(根据时间变化的自行车数量)。但在其他的预测任务中,可能有多维的数据出现的情况。
在这个函数的最后,我们用 list 返回 X_train, y_train, X_test, y_test 。
创建模型
def build_model():
model = Sequential()
layers = [1, 50, 100, 1]首先从Keras创立一个 Sequential 对象,这代表我们将在这个Sequential 对象的基础上一层一层堆叠我们的模型。 layers 记录着四个数字,代表着每一层的大小。
我们的网络有1维的数值输入,两个隐含层(两层LSTM)的输出结果的数量分别为50和100,最后一层(output layer)的输出层维度为1,代表着预测结果。
model.add(LSTM(
layers[1],
input_shape=(None, 1),
return_sequences=True))
model.add(Dropout(0.2))模型初始化以后,我们创建了第一层(LSTM,输入为某个序列中的一个数字),因为我们的输入是一维的,所以我们定义输入input_dim纬度为 1。然后我们定义了这一层需要 layers[1] 个输出数量,同时在这一层添加了 20%的 Dropout 。如果输出的数量越多,说明我们有越多的矩阵来描述更多的特征,数量越多越容易产生过拟合,所以需要Dropout。
model.add(LSTM(
layers[2],
return_sequences=False))
model.add(Dropout(0.2))第二层更简单,直接填写我们期望的输出数量 (layers[2])就可以了,Keras会自动处理上一层输入操作等等。
model.add(Dense(
layers[3]))
model.add(Activation("linear"))最后一层我们使用 Dense ,也就是说把上一层的输出结果全都乘以一个矩阵,最终得到一个数(layers[3]=1)。 由于我们这是在进行线性回归操作,所以激活函数填 linear 。
start = time.time()
model.compile(loss="mse", optimizer="rmsprop")
print("Compilation Time : ", time.time() - start)
return model我们使用 MSE(Mean Square Error)进行误差计算,优化函数选择 RMSprop (线性回归问题的的标准做法)。
Return_Sequence
直到目前为止我们还没有看 return_sequence= 这个参数在 LSTM 层中的作用。我们用 Andrej Karpathy 的这张经典的RNN示意图来理解这个参数的作用。下图中红色的代表序列输入,绿色的代表展开的 LSTM 神经元,蓝色代表输出。注意到绿色的有两个输入,一个是来自上一个自己,另一个来自现在的输入。
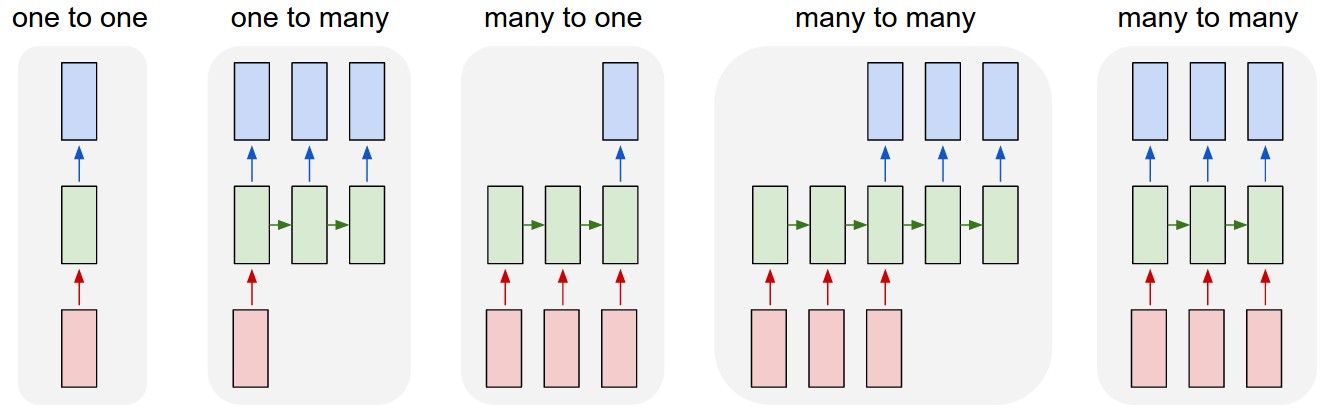
return_sequence=True 主要是上图的第五种情况(多对多的关系), return_sequence=False 主要是上图的第三种情况(多对一的关系)。
在本文的案例中,第一层 LSTM 将逐一返回结果到下一层和下一个自己。因为我们希望把每一次的输出信息都输入到下一层LSTM作为训练数据(箭头向上),也同时也将信息传给下一个自己作为输入数据(箭头向右)。
但是第二层LSTM中,我们只希望19个输入的值中的最后一个值产生的结果与真实值进行对比。第二层LSTM中,前18个值只是将他们输出值传给了这一层本身,作为下一次运算的输入值,而且并没有同时传给下一层。然而在第19输入的时候,第二层LSTM将这次的输出结果传给了下一层 Dense ,然后在 Dense 层结合真实值进行loss计算和优化等操作。
更详细的解释
如果你还不是特别清楚的话,我们举一个更简单的例子,把序列的长度设为4,这样就是用前3个去预测第4个。前三个为输入值,第四个为真实值。
-
输入序列的第一个值输入网络
a. 第一层 LSTM 得到第一个输入,并开始运算,然后将运算结果同时传给了下一层和自己。
b. 第二层 LSTM 得到从第一层传来的运算结果作为输入,开始自己的运算,并只将结果传给自己。
-
输入序列的第二个值输入网络
a. 第一层 LSTM 将第二个输入和上第一次计算的结果同时作为输入,进行计算,然后将运算结果同时传给了下一层和自己。
b. 第二层LSTM表现和上一次一样,从第一层传来的运算结果和自己上一次的运算结果作为输入,再次开始自己的运算,并只将结果传给自己。
-
输入序列的最后一个值输入网络
a. 第一层 LSTM表现如 (2.a)
b. 第二层 LSTM表现与 (2.b) 基本一样,但这一次第二层将运算结果也同时传给了下一层 ,
Dense层。c.
Dense层计算自己输出结果,也就是我们最终的预测值(第四个值的预测值)。
这里的每一层的运算结果跟我们之前所定义的输出大小密切相关,之前第一层LSTM的输出结果定义为50,第二层为100,最后的输出层为1。他们通过构造矩阵相乘的方式来得到你所定义的结果。
综上所述 ,实际上 return_sequence=True 在第一层中的含义是将每次的计算结果都同时传给下一层。从一次序列输入的整体过程来看,第一层不停向下一层输入的计算结果实际上也是根据最初的输入得到的一个时间序列。
另一方面,第二层设置 return_sequence=False 的原因是下一层只需要最后一个输入序列的预测结果,所以在最后一个值计算完成后,将结果传同时给下一层。从一次序列输入的整体过程来看,第二层LSTM并没有产生一个时间序列,而是产生了一个预测向量(大小是我们之前定义的 layer[2] ,也就是100)。最后的 Dense 层用于集中这个预测向量中所有的信息,并通过矩阵相乘的方式得到最终的预测值(第四个值的预测值)。
如果我们连续堆砌三个 RNN 的隐含层,那么我们就需要把前两个设置成 return_sequence=True ,最后一个设置为return_sequence=False 。换句话说, return_sequence=False 被用于 RNN 层与 Feedforward 层(卷积神经网络、Fully-connected神经网络等)之间连接的桥梁。
运行神经网络
def run_network(model=None, data=None):
epochs = 30
path_to_dataset = 'bike_rnn.csv'
if data is None:
print('Loading data... ')
X_train, y_train, X_test, y_test = get_data(
path_to_dataset, sequence_length, ratio)
else:
X_train, y_train, X_test, y_test = data
print('\nData Loaded. Compiling...\n')
if model is None:
model = build_model()为了模块化的考虑,我们首先分别请求 data 和model 。
try:
model.fit(
X_train, y_train,
batch_size=512, nb_epoch=epochs, validation_split=0.05)
predicted = model.predict(X_test)
predicted = np.reshape(predicted, (predicted.size,))
except KeyboardInterrupt:
print('Training duration (s) : ', time.time() - global_start_time)
return model, y_test, 0然后开始训练模型,调用 model 的 fit 方法。这里我们重点关注一下predicted方法。
- 根据我们之前的构造,
X_test是一个个长度为19的时间序列(也可以叫做作19个timesteps),第20个实际上是我们希望预测的值。 X_test[0]就是第一个输入序列,包括19个连续的自行车数量。predict(X_test[0])的意思是通过这个序列预测第20个时刻的自行车数量,它的真实值是y_test[0]。实际上根据我们之前的构造,y_test[0] = X_test[1][18] = X_test[2][17] = ...- 所以
predict(X_test[1])是在预测原始序列的第21个值,它的真实值是y_test[1]。 - 所以
predict(X_test)预测出来的是一大串数值,实际上正好和y_test整体一一对应。 predict(X_test)是一个 list 包含着很多个 list 的numpy数组,我们最终把最里面的 list 内容 reshape 成一个个一维数组。(比如[200, 20] 变成了 [200, 20, 1])
try:
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(y_test[:100, 0])
plt.plot(predicted[:100, 0])
plt.show()
except Exception as e:
print(str(e))
print('Training duration (s) : ', time.time() - global_start_time)
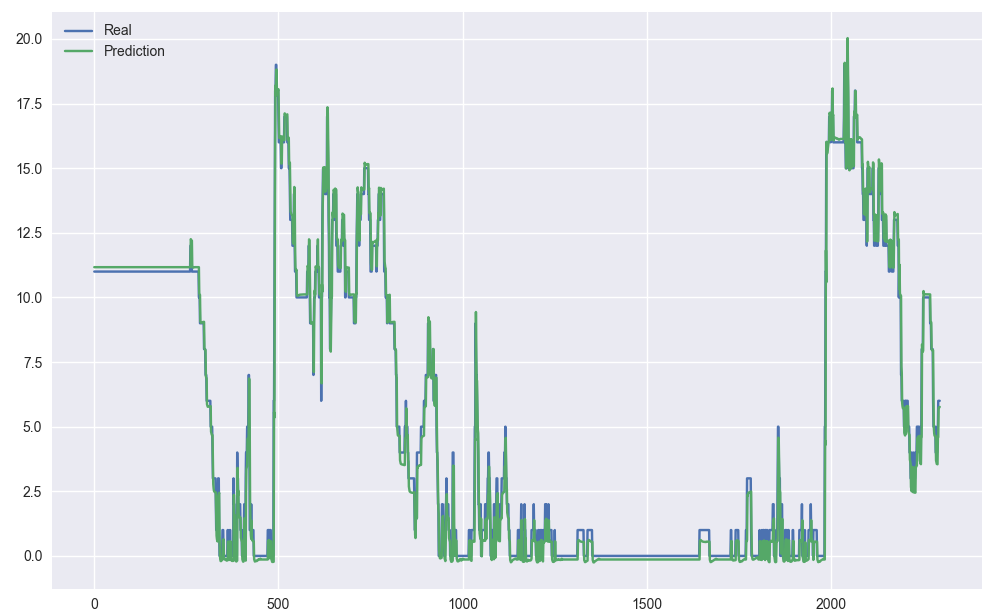
return model, y_test, predicted最终我们把前100个预测结果和真实值画出来,并返回 model, y_test 还有 predicted 预测值。
总结
- 除了 LSTM 外,可以换成GRU 等其他的RNN模型尝试一下
- 除了 num 字段外,weekday 和 hour 也是有用的,如何利用这两个字段的信息?如何构建更复杂的神经网络模型?希望大家能进一步的探索交流。
- 本文的输出仅仅为1个timestep,实际上可以是连续的多个,感兴趣可以自己动手试试
- 应该如何设定层数,output个数,dropout比例等等是一门艺术。如何优化超参数是也是个比较棘手的问题,参数的设定往往决定着模型的好坏。不出意外的话,下一篇博客讲一讲怎么优化这些 Hyperparameters。
感谢阅读以上内容。本人才疏学浅,如有错误欢迎批评指正,resuly@foxmail.com
数据与完整程序下载 code.zip
References
Daniel Hnyk: http://danielhnyk.cz/predicting-sequences-vectors-keras-using-rnn-lstm/
Vict0rSch: https://github.com/Vict0rSch/deep_learning/tree/master/keras/recurrent
Jason Brownlee: http://machinelearningmastery.com/time-series-forecasting-long-short-term-memory-network-python/
DENNY BRITZ: http://www.wildml.com/2016/08/rnns-in-tensorflow-a-practical-guide-and-undocumented-features/